As compared to last year, artificial intelligence (AI) has seen a significant breakthrough in developing large language models (LLMs). These models are based on deep learning algorithms and are capable of understanding, generating, and predicting new content.
In simple terms, A large language model is a type of artificial intelligence algorithm that is trained on a massive amount of data to predict upcoming words and sentences based on the context of previous text. These models are based on deep learning techniques, which allow them to learn from vast amounts of data and improve their performance over time.
ELIZA, The first AI language model can be traced back to 1966, but large language models use a significantly larger pool of data for training, which means a significant increase in the capabilities of the AI model.
One of the most common applications of LLMs right now is generating content using AI chatbots. More and more are popping up in the market every day as competitors.
⚙️
The more data we use to train an LLM, the more accurate it becomes.
Characteristics of LLMs:
- Large Training Data: LLMs ingest massive text corpora during training, typically hundreds of gigabytes to terabytes in size. Popular training datasets include Common Crawl, Wikipedia, news articles, books, and web content.
- Neural Network Architecture: LLMs use neural networks as their core architecture. The neural networks have multiple layers that map complex relationships between words.
- Self-Supervised Learning: LLMs are trained using self-supervised learning, where the model learns by predicting masked or missing words in the training data. No human labelling is required.
- Transfer Learning: Pre-trained LLMs can be fine-tuned on downstream tasks using transfer learning. This adapts the model for new applications while retaining its core understanding of language.
Some of the most well-known LLMs include Google’s PaLM & BERT, OpenAI’s GPT-3, and Anthropic’s Claude. Over time, LLMs are becoming larger in size and more capable.
| Models | Data Size | Company | Launch Date |
|---|---|---|---|
| GPT-4 | 1+ trillion parameters | OpenAI | March 2023 |
| GPT-3.5 | 175 billion parameters | OpenAI | Not Available |
| PaLM | Not Available | Not Available | |
| LaMDA | Not Available | Not Available | |
| Claude | Not Available | Anthropic | March 2023, July 2023 for Claude 2 |
| LLaMA & LLaMA 2 | 7B, 13B, 33B, and 65B parameters for LlaMa, and from 7B to 70B parameters for LlaMa 2 |
Meta AI (Facebook) | February 2023 for LlaMa and July 2023 for LlaMa 2 |
| Falcon | 180 billion parameters | Technology Innovation Institute | Not available |
AWS ECR vs Docker Hub
When it comes to container registry, two of the most popular options are AWS Elastic Container Registry (ECR) and Docker Hub.

Most modern LLMs are based on transformer neural networks, a type of network architecture particularly well-suited for processing sequences like text. The transformer uses an attention mechanism to understand how words relate to one another based on their positioning in the text.
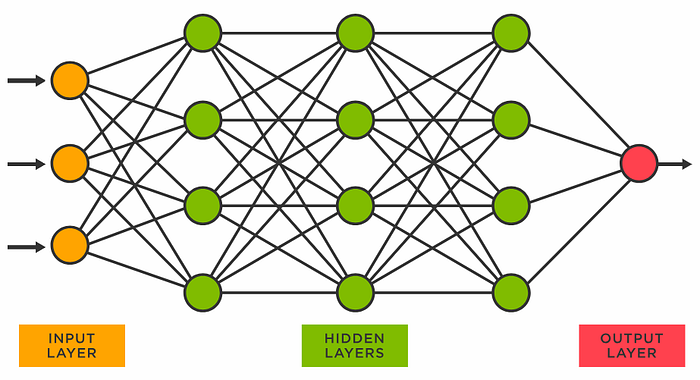
Some key components of the transformer architecture include:
- Encoder: Reads and encodes the input text into vector representations. Learns contextual relationships between words.
- Decoder: Generates predictions for the next word or sequence based on the encodings.
- Attention: Allows focusing on relevant parts of the input text when making predictions. Draws connections between words.
- Embedding Layers: Transform words into numerical vector representations. Words with similar meanings have similar embeddings.
- Feed Forward Layers: Propagate information through the network to refine and adjust predictions.
By stacking multiple transformer blocks together, very deep language understanding models can be built.
What is Quantum Computing?
Quantum computing is an advanced technology that has the potential to significantly transform our understanding of computing and problem-solving.

A key ingredient for LLMs is the massive amount of text data they are trained on. The more varied, high-quality data they ingest, the better the models become at understanding the nature of language.

Popular training datasets for LLMs include:
- Web Pages: Web-crawled datasets like Common Crawl which contain petabytes of webpage data.
- Books: Digital book archives like Project Gutenberg (60,000 books).
- Wikipedia: The entire English Wikipedia contains over 6 million articles.
- News Articles: Aggregated newswire data from outlets like the New York Times.
- Scientific Papers: Corpus of academic papers and journals.
- Discussion Forums: Data from Reddit, StackOverflow and other forums.
This highly diverse training data allows LLMs to model a wide range of topics, writing styles, and language structures.
What is Vector Database and How does it work?
Vector databases are highly intriguing and offer numerous compelling applications, especially when it comes to providing extensive memory.
LLMs are trained using a self-supervised approach rather than needing manual human labelling.

In self-supervised learning, the model learns by predicting missing words or sequences from the training data. For example:
- The man walked down the [MASK] street.
The model must predict the most probable word that should fill the [MASK] based on the context – which in this case would be “quiet”.
By repeating this process across massive datasets, the model progressively learns the patterns and relationships in language from the ground up.
This approach removes the need for manual labelling while still teaching the model to generate high-quality text.
VPN vs. Zero Trust Network: Which is More Secure for Remote Access?
Zero trust fixes vulnerable trust models and limited visibility in VPNs by verifying all users and devices, encrypting everything, and monitoring all activity – before authorizing access.

LLMs work by using unsupervised learning. This means that the model is trained on a large dataset of text without any specific labels or annotations. The model then uses this data to learn the patterns and structures of language, allowing it to generate new content that is similar to human language.
The training process for LLMs is complex and requires a significant amount of computational power. The model is trained on a massive amount of text data, such as books, articles, and websites. The model then uses this data to learn the patterns and structures of language, allowing it to generate new content that is similar to human language.

Once the model is trained, it can be fine-tuned on a smaller, more specific dataset. This process is called fine-tuning, and it allows the model to become an expert at a specific task. For example, businesses can use LLMs to create intelligent chatbots that can handle a variety of customer queries, freeing up human agents for more complex issues.
The Most Popular APIs: REST, SOAP, GraphQL , and gRPC Explained
Learn about the most popular APIs – REST, SOAP, GraphQL, and gRPC. Understand their features, use cases, and differences between them.

1. Natural Language Generation
LLMs can generate coherent, human-like text for a given prompt or context. This makes them useful for applications like:
2. Text Summarization
LLMs can digest long passages of text and summarize the key points concisely. This is helpful for:
- Summarizing articles, reports, scientific papers
- Generating meeting notes and highlights
- Pulling key insights from customer feedback
3. Sentiment Analysis
Understanding sentiment and emotion in the text is another strength of LLMs. Applications include:
- Social media monitoring and analytics
- Gauge reactions to marketing campaigns
- Analyze customer satisfaction in surveys
- Flag toxic comments and content
4. Question Answering
LLMs can answer questions about a context they are given. This enables:
- Conversational AI chatbots
- Intelligent product search
- Answering customer/user queries
- Automated tutoring and education
5. Text Classification
LLMs can categorize documents like:
- Organize news articles by topic
- Tag customer support tickets
- Classify content for recommendation engines
- Extract key information from documents
While pre-trained LLMs have strong general language abilities, they can be customized for specific tasks through fine-tuning:
- Start with a pre-trained LLM like BERT or GPT-3
- Add task-specific training data like labelled classification examples
- Train the LLM on the new data, adjusting the internal parameters for the task
- The model retains its core knowledge but gains specialized skills
For example, a sentiment analysis model could be created by fine-tuning an LLM on a dataset of movie reviews labelled with their sentiment scores.
Fine-tuning is much faster than training a model from scratch. It also allows easier customization for different use cases.
- Training Data Bias: Training datasets may contain unwanted biases that are reflected in the model’s behaviour.
- Hallucinated Content: LLMs may fabricate plausible-sounding but incorrect facts.
- Toxic Language Generation: Without moderation, LLMs can produce harmful, biased, or abusive language.
- High Compute Requirements: Training and running LLMs requires powerful, expensive hardware.
- Lack of Reasoning: LLMs have limited capabilities for logical reasoning and inference.
- Exposure to Sensitive Data: Private data may need protection when training LLMs.
Large language models are big improvements in AI’s ability to understand language naturally. This is because of neural networks designed for text, huge amounts of training data, and self-supervised learning. These let LLMs gain a very deep understanding of how language works and what it means.
This allows LLMs like GPT-3 to generate amazingly human-like text, while also enabling valuable applications in areas like text generation, summarization, sentiment analysis, question answering, and classification. Fine-tuning provides a path to customize LLMs for specialized use cases.
While promising, LLMs also come with challenges related to bias, reasoning, computing requirements, and potential risks. Responsible development practices combined with ongoing innovation promise to yield even more capable and beneficial LLMs that augment human abilities.
What is Database Sharding?
Database sharding is a technique that splits a database into smaller shards to improve performance, scalability, and availability.

What Are the Different Types of Databases?
Learn about the various types of databases, including relational, NoSQL, and graph databases. Explore their features and benefits.

What Makes Load Balancer vs. API Gateway Different and Use Cases ?
Discover the key distinctions between Load Balancer and API Gateway, along with their unique use cases like efficient traffic distribution & integration.
FAQs
What are some examples of large language models?
Some prominent examples of large language models include OpenAI’s GPT-3, Google’s BERT, Meta’s OPT, Anthropic’s Claude, Microsoft’s Turing NLG, and BLOOM by Hugging Face. These contain billions to trillions of parameters and are trained on massive text datasets.
How is GPT-3 different from previous language models?
GPT-3 achieves a major leap forward in scale and performance compared to previous models. It has 175 billion parameters, allowing much greater complexity. GPT-3 is also trained on a huge 450 GB dataset and shows significantly improved text generation abilities.
What types of neural networks are used in LLMs?
Most modern large language models are based on transformer neural network architectures. Transformers are specifically designed for processing sequential data like text and excel at learning context and relationships between words.
What is transfer learning?
Transfer learning refers to the process of taking a pre-trained LLM and fine-tuning it on data from another task. This allows the model to adapt to new applications while retaining its generalized language knowledge. For example, an LLM could be fine-tuned to classify legal documents after initial training on Wikipedia.
What are the risks associated with large language models?
Potential risks include propagating biases, toxicity, or misinformation based on flaws in training data, privacy issues from exposure to personal data, generating false content, and malicious use of synthetic media created by LLMs. Responsible development and monitoring help mitigate these concerns.
What is the difference between supervised and unsupervised learning for LLMs?
LLMs predominantly use unsupervised learning, where the model learns patterns from unlabeled text data. This differs from supervised learning where humans label and categorize the training data. Unsupervised learning allows LLMs to train on much larger datasets since labelling is not required.
How are LLMs making chatbots and voice assistants more capable?
LLMs are making conversational agents by providing greater abilities for natural language understanding and text generation. This allows chatbots powered by LLMs to handle more complex dialogue and questions compared to previous rule-based chatbots.
Can LLMs understand human emotions and non-verbal cues?
Currently, LLMs have limited capabilities to detect human emotions, moods, and non-verbal cues since they only process text data. However, research is ongoing into multimodal LLMs that can analyze tones, facial expressions, and empathy signals to enhance emotional intelligence.
What are the computational requirements for training and running LLMs?
Training and running large language models requires vast amounts of computational resources, typically using hundreds or thousands of GPUs and TPUs. Companies like OpenAI, Google, and Nvidia have invested heavily in specialized supercomputers optimized for LLMs.
How might LLMs impact content creation jobs in the future?
LLMs may assist humans in content creation workflows, such as helping generate drafts or ideas faster. However current limitations in reasoning and judgment mean they are unlikely to fully automate creative fields. Responsible development guidelines will be important as capabilities improve over time.