
{kind=link}
Linear Regression in Machine Learning is one of the most fundamental techniques that a learner gets his hands on in the beginning. It is one of the most simplistic yet powerful algorithms used in various problem scenarios in the context of Machine Learning. As you can guess, Linear Regression is named “Linear” in itself, meaning that a linear, straight relationship is present somewhere in it. In a nutshell, Linear regression is all about finding the best-fitting line through a scatterplot of data points.
What is Linear Regression in Machine Learning?
Linear Regression is a supervised machine learning algorithm used for predicting a continuous target variable based on one or more independent variables. It establishes a linear relationship between the input variables and the output. Linear Regression is a simple yet powerful supervised learning algorithm used to understand and predict the association between two variables.
This relationship is expressed as:
y=mx+b
Where:
- y is the target variable.
- x is the input feature(s).
- m is the slope of the line.
- b is the y-intercept.

In linear regression, we have a dependent variable (y), which we want to predict or understand, and one or more independent variables (x), which are used to make predictions. The goal is to find the best-fit line that minimizes the distance between the line and the actual data points. The line is defined by two parameters: the intercept (where the line crosses the y-axis) and the slope (the steepness of the line). These parameters are estimated using a technique called “ordinary least squares,” which minimizes the sum of the squared differences between the predicted values and the actual values.
Once we have the best-fit line, we can use it to make predictions.
Mathematically, we represent the Linear Regression hypothesis function as follows:

where:
- hθ(x) is the predicted output (hypothesis) for input x
- θ0 is the y-intercept (the value of y when all x variables are zero)
- θ1, θ2, …, θn are the coefficients (weights) corresponding to each x variable
- x1, x2, …, xn are the input (feature) variables
Cost Function and Gradient Descent
Cost Function measures the difference between the actual values of our target variable and the predicted values by the linear regression model. Here the goal of the cost function is to minimize this difference and make the cost function as small as possible, and eventually predictions as accurate as it can.
The cost function can be represented as:
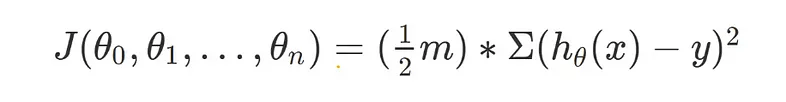
where:
- J represents the cost function
- m is the total number of data points
- hθ(x) is the predicted output (hypothesis) for input x using the theta values
- y is the actual target value
While linear regression is powerful, it often involves optimizing a cost function to find the best-fitting line. Gradient Descent comes into play as a crucial optimization technique in this context. It helps us find the optimal values for m (slope) and b (y-intercept) that minimize the cost function.
Gradient Descent is an iterative optimization algorithm used to find the minimum of a function, in our case, the cost function in linear regression. It works by adjusting model parameters iteratively in the direction of the steepest descent (negative gradient) to reach the minimum. During each step, the algorithm updates the parameter values based on the gradients and the learning rate.
The learning rate determines the size of the steps taken in the descent. If the learning rate is too small, the algorithm may converge slowly. On the other hand, if it’s too large, the algorithm may overshoot the minimum and fail to converge.
The process continues iteratively until the algorithm reaches a point where the cost function is minimized, or a predefined number of iterations is reached. At this point, the parameter values correspond to the best-fitting line that minimizes the difference between the predicted and actual values.
How Does Gradient Descent Work?
- Initialization: Start with initial values for m and b.
- Compute Gradient: Calculate the gradient of the cost function with respect to m and b.
- Update Parameters: Adjust m and b using the gradient and a learning rate.
- Repeat: Continue these steps until convergence
Gradient Descent Can be represented as:
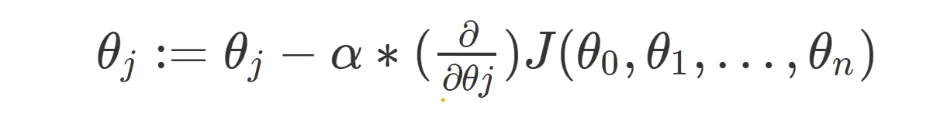
where:
- θj represents the j-th theta value (coefficient)
- α is the learning rate (step size)
- (∂/∂θj) J(θ0, θ1, …, θn) represents the partial derivative of the cost function J with respect to θj
Assumptions of Linear Regression
Linear Regression assumes certain things in these cases, such as:
- Linearity: The relationship between the independent variables and the dependent variable is assumed to be linear.
- Independence: The observations used in the regression model are assumed to be independent of each other. This means that there should be no relationship or correlation between the residuals or errors of the model.
- Homoscedasticity: The variability of the residuals or errors across the range of the independent variables should be constant. In other words, the spread or dispersion of the residuals should be consistent across different levels of the predictors.
- Normality: The residuals or errors of the model are assumed to be normally distributed. This assumption is important for making statistical inferences and conducting hypothesis tests.
- No multicollinearity: The independent variables used in the model should not be highly correlated with each other. High multicollinearity can lead to unstable estimates and make it difficult to interpret the individual effects of the predictors.
Types of Linear Regression
There are generally 2 types of Linear Regression Algorithms in Machin Learning:
Simple Linear Regression
Simple linear regression in machine learning is a technique used to understand and predict the relationship between two variables. In simple linear regression, we have a dependent variable (the one we want to predict) and an independent variable (the one we use to make predictions).
Let’s say, we want to predict a person’s salary based on their years of experience. The number of years of experience would be our independent variable, while the salary would be the dependent variable. Simple linear regression finds a straight line that best fits the data points, in this way, we can make predictions for new or unseen data.
Multiple Linear Regression
Multiple linear regression expands on simple linear regression by considering multiple independent variables. Instead of just one variable, we now have multiple variables that may influence the dependent variable. This enables us to create a more comprehensive model that takes into account various factors.
Let’s take an example where we want to predict the price of a house based on its size, number of bedrooms, and location. In multiple linear regression, we can incorporate all these variables to build a predictive model. The goal is to find the best-fitting line that considers the combined effect of these variables on the house price.
By using multiple linear regression, we can better capture the complexity of real-world scenarios where several factors may influence the outcome. It allows us to examine the individual impact of each independent variable while considering their combined effect on the dependent variable.
In both simple and multiple linear regression, the model estimates the relationship between the variables by calculating the coefficients for each independent variable. These coefficients represent the slope of the line and indicate the strength and direction of the relationship.
Evaluating Linear Regression Models in Machine Learning
When it comes to evaluating linear regression models, there are several methods you can use to assess their performance and determine their effectiveness. These evaluation techniques help you understand how well your model fits the data and how reliable its predictions are. Let’s see some of the common approaches for evaluating linear regression models:
Mean Squared Error (MSE): MSE measures the average squared difference between the predicted and actual values. It calculates the sum of the squared residuals and divides it by the number of data points. A lower MSE indicates a better fit for the data.

Where:
– n is the number of data points
– y represents the actual values
– ŷ represents the predicted values
Root Mean Squared Error (RMSE): RMSE is the square root of the MSE and provides an easily interpretable measure of the average prediction error. It is in the same unit as the target variable, making it more intuitive to understand.

R-squared (R²) or Coefficient of Determination: R-squared measures the proportion of the variance in the dependent variable that can be explained by the independent variables. It ranges from 0 to 1, where 1 indicates a perfect fit. However, R-squared alone does not indicate the model’s predictive power, so it should be interpreted alongside other evaluation metrics.

Where:
— SSR is the sum of squared residuals (Σ(y — ŷ)²)
— SST is the total sum of squares (Σ(y — ȳ)²), where ȳ is the mean of the actual values (y)
Applications of Linear Regression Models in Machine Learning
- Predictive Analytics and Forecasting: Linear regression is widely used for predicting future outcomes based on historical data. For example, it can be applied to predict stock prices, sales volumes, or demand for a product. By analyzing trends and patterns in the data, linear regression can provide valuable insights for making informed business decisions.
- Financial Modeling and Investment Analysis: Linear regression plays a crucial role in financial modeling. It can help analyze the relationship between different financial variables, such as interest rates, GDP growth, and stock prices. Financial analysts and investment professionals use linear regression to forecast market trends, evaluate risk, and make investment decisions.
- Customer Relationship Management (CRM) and Market Analysis: Linear regression is employed to understand customer behavior, preferences, and purchasing patterns. By analyzing customer data, businesses can identify factors that influence customer satisfaction and loyalty. Linear regression models can also be used for market segmentation, pricing strategies, and optimizing marketing campaigns.
- Healthcare and Medical Research: Linear regression is utilized in healthcare for analyzing medical data and making predictions. It can be used to study the relationship between patient characteristics and treatment outcomes. Linear regression models are used in medical research to investigate the impact of various factors on disease progression, patient recovery, or treatment effectiveness.
- Social Sciences and Behavioral Analysis: Linear regression is widely used in social sciences to study human behavior and analyze survey data. It can help understand factors influencing educational outcomes, economic trends, or social phenomena. Researchers use linear regression to explore relationships between variables and make predictions based on social and behavioral data.
Conclusion
In this article, we discussed in-depth Linear Regression in Machine Learning, and the entities related to it such as hypothesis function, cost function, gradient descent, etc. You can use Scikit-Learn to implement linear regression models in your project. Feel free to drop your doubts in the comments below if you have any. I hope you got a good overview of the Linear Regression algorithm in Machine Learning.